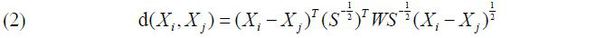- P-ISSN 2586-2995
- E-ISSN 2586-4130

Government R&D grants for SMEs have risen to three trillion Korean won a year, placing Korea second among OECD nations. Indeed, analysis results have revealed that government support has not only expanded corporate R&D investment and the registration of intellectual property rights but has also increased investment in tangible and human assets and marketing. However, value added, sales and operating profit have lacked improvement owing to an ineffective recipient selection system that relies solely on qualitative assessments by technology experts. Nevertheless, if a predictive model is properly applied to the system, the causal effect on value added could increase by more than two fold. Accordingly, it is important to focus on economic performance rather than technical achievements to develop such a model.
R&D Policy, SMEs, Program Evaluation Genetic Matching, Heterogeneous Causal Effect
O32, O38
An amount of 8.1 trillion won, 40 percent of the entire national annual R&D budget (19 trillion won) was allocated for economic growth including industrial and infrastructure development, in 2016. Among these funds, three trillion was earmarked for the innovation of SMEs in the form of R&D grants, making Korea the second largest spender in absolute amounts among OECD members, next to the US and ahead of Germany and Japan. Moreover, due to the government’s direct grants and indirect tax benefits, the yearly R&D investment of Korean SMEs exceeded 13 trillion won during the same year (36,026 affiliated research institutes). Korea also ranks fourth in total corporate R&D and second in SME R&D among OECD nations, as shown in Table 1.1 In particular, small firms with fewer than 50 employees, including startups, were found to invest more actively in R&D than medium-sized firms.2
Note: Figures in parentheses denote government-funded R&D costs.
Source: Main Science and Technology Indicators (OECD Stat webpage). Cited from Park et al. (2016) pp.24-25.
Prior literature on the performance evaluation of R&D support projects have mainly focused on how support contributes to increasing corporate R&D investment and intellectual property (IP) rights, and the majority of outcomes have shown a positive relationship. However, with the exception of Oh and Kim (2017), very few studies have dealt with the economic gains of R&D support. Oh and Kim (2017) looked at growth indicators (sales, employment, assets, and liabilities), profitability indicators (ROA, ROE, operating margin), and R&D investments by firms to assess the economic gains from governmental R&D support. This study adds value added and various strategic assets to the list of economic indicators. Value added is the most comprehensive indicator, and not only knowledge capital such as R&D but also physical capital, human capital, and relational capital may contribute to the growth of value added. Indeed, with governmental R&D grants for SMEs reaching the three trillion won mark, this study attempts to assess the contribution of government support projects comprehensively along with other strategic assets and to seek ways to enhance the effectiveness of these sources of funding.
The Small Business Innovation Research (SBIR) program is the main R&D support program for SMEs in the US. In 2015, the SBIR program distributed about $2.5 billion via eleven departments.
Edison (2010) examined 1,460 companies applying for US Department of Defense (DOD) SBIR funding in 2003 and found a significant causal effect of increased sales of recipients by $0.15 million during the following year ($0.37 million in 2004-2006). In addition, Howell (2017) analyzed the earnings of 5,021 companies applying for US Department of Energy (DOE) SBIR funding in 1995-2013 and confirmed that grants awarded during Phase Ⅰ (the proof-of-concept stage with funds up to $0.15 million for 6-9 months) increased the average 10% probability of venture capital funding by +10%p and $2 million in sales by $1.3-$1.7 million. The results also revealed that the increases were not due to the effects of government certification; instead, they stemmed from the effects of proof-of-concept demonstrated via prototypes. Moreover, increases in venture capital funding were particularly strong among firms without patents and young startups less than two years old (+6%p and +14%p). On the other hand, the extensive grants given during Phase Ⅱ (the subsequent full-scale R&D with funds reaching $1 million for a period of 24 months) had little economic impact. Accordingly, Howell (2017) concluded that rather than offering large long-term funding to a few medium-sized firms, it would be more effective to award small lump sums to numerous small-sized firms. Germany and Finland operate similar programs, providing small grants and research consulting services to such firms and startups which lack R&D experience. Most R&D support programs in advanced economies have transparent and convenient online management systems that accommodate free competition for bottom-up research designs.
Based on the SBIR, the Korean government established the Korea Small Business Innovation Research (KOSBIR) program in 1998 and has steadily increased this budget since. Indeed, the expenditure for SME-operated government R&D projects reached 2,897 billion won in 2016, equivalent to 15.2% of the government’s total R&D investment amount and similar to the US SBIR’s total grant amount.3 According to the National Science and Technology Knowledge Information Service (NTIS) database, which includes information pertaining to the management of all government R&D projects, among the 30,448 R&D projects awarded to firms in 2010-2014, the median funding amount was 200 million won, while the top 20% ranged from 525 million to 54.7 billion won and the bottom 20% accounted for less than 100 million won. In the US, Phase Ⅰ projects (about $0.10 million per project) outnumbered Phase Ⅱ projects by two to three fold. However, in Korea, nearly 80% of projects were funded at more than 100 million won per project, implying a strong tendency to omit the initial proof-of-concept stage and begin with full-fledged support.
Governments evaluate R&D support projects in terms of patents and publications. Patent applications for SMEs continued to soar due to their strong commitment in acquiring more patents, rising from 34,547 in 2013 to 46,813 in 2016.4 On the other hand, that number for large enterprises declined from 48,045 to 38,800 over the same period following a shift in the evaluation focus of R&D divisions to the creation of economic value after it was deemed that practices such as stockpiling unused patents simply to demonstrate technological prowess was a waste of financial (patent applications and renewal fees) and research resources.
This study used the Korea Enterprise Data (KED) (2010-2015) to analyze the economic effects of government support programs. Research subjects were limited to incorporated enterprises with more than ten employees. The 2010-2015 financial performance outcomes of a total of 212,245 firms were analyzed of which 165,023 small-sized firms and 42,770 medium-sized firms were the main focus of the analysis. In this study, 70% or 21,265 cases in the NTIS were linked to our dataset.
Based on the financial data, this study extracted ten performance indicators pertaining to the following three aspects: operating performance (value added, sales and operating profit), financing (debt and equity) and capabilities/assets.5 Value added is the most comprehensive indicator, as it covers all value distributed to various stakeholders, including employees (labor cost), shareholders (dividends), government (taxes and dues), creditors (interest), and firms (net profit + depreciation cost). Additionally, despite the significance of economies of scale in the past, the scalability of intangible assets has grown in importance, as shown by Uber and Airbnb. Thus, in terms of performance indicators for capabilities/assets, this study used R&D investment, IP rights registrations and marketing investment in conjunction with tangible assets and human capital investment.6
Table 2 shows that recipients considerably outperformed non-recipients on average in terms of most indicators, specifically operations, financing and capabilities/assets when they receive subsidies. The differences are statistically significant, and the differences in the operating profit and R&D investment indicators widen by more than twenty times. However, there is a visible reverse in this trend two to three years after the reception of support, except for IP rights registrations. Even operating profit and R&D investment decrease.7 When large enterprises are included in the comparison, negative growth can also be observed in value added and marketing investment.
Existing econometric studies usually estimate causal effects with a parametric model, which is created by assuming the form of the functions and distribution of the data. However, models based on hard-to-verify assumptions always run the risk of misspecifications. Matching methods (matching observations which have different values of the treatment variable and similar values of other covariates) are widely used to estimate causal effects from observed data in the absence of random experimental data, although the matching method cannot account for the effects of unobserved variables. Matching methods, as non-parametric preprocessing approaches, can compensate for the weaknesses of parametric models. Ho, Imai, King and Stuart (2007) suggest a two-step unified estimation approach which integrates a non-parametric matching method and the parametric regression model. The two-step approach can accurately estimate causal effects even when only one of the two steps is properly specified. Hence, it is doubly robust and can also estimate the effects of other covariates.
In this study, diverse methods were attempted in the matching phase. Propensity score matching (PSM) satisfies the unconfoundedness assumption (Yi(1), Yi(0)) ⊥Ti | X by replacing multi-dimensional covariates (X) with propensity scores (P(X)). PSM usually uses parametric models such as the logistic and probit models to convert multivariate covariates into one-dimensional propensity scores. The values of the closest propensity scores in the experimental group and the control group are then matched one-to-one with each other. Alternatively, the weight is given in proportion to the proximity of the propensity score. However, King and Nielsen (2016) suggest that alternative matching methods should also be tested because PSM can aggravate imbalance, inefficiency, model dependence and bias. Specifically, it is difficult to satisfy the conditional independence between the covariate and treatment variable depending on a single parametric model given that there is a complex decision-making system in reality. The lack of computing power in the past made PSM useful, but matching based on multi-dimensional covariates has become affordable owing to the advancements in computing power.
Mahalanobis Distance Matching (MDM) is also one of the most widely used matching methods. PSM and MDM are equal-percent bias-reducing (EPBR) methods, meaning that they reduce the bias by the same rate through a linear combination of covariates (Kim, 2016). EPBR methods can reduce bias only when the dataset of covariates can be modeled using a Gaussian (normal) distribution. Because the distribution of real data is often not Gaussian, a matching method based on a linear combination may rather increase the bias.
Iacus, King, and Porro (2009) developed the Coarsened Exact Matching (CEM) method, which divides the covariates into coarse intervals and then precisely matches the same interval units. Imbalances cannot be larger than the block range predefined by a researcher and an improvement in the balance for one covariate does not affect the imbalance of the other covariates. However, CEM may leave many cases in the treatment group unmatched with the control group. If the interval of the covariate blocks is widened to increase the matching rate, imbalances will increase as a trade-off.
Another alternative matching method is Genetic Matching (GM), which optimizes the balance of covariates using a genetic algorithm (Sekhon, 2011).8 The Mahalanobis distance is defined as follows:
In equation (1), S is the sample covariance matrix of X . If the covariate contains continuous variables, there is a bias that does not disappear (Abadie and Imbens, 2006). The GM algorithm adds a square matrix of weights W to generalize the Mahalanobis metric when the Mahalanobis distance does not optimally approach equilibrium. The equation for the GM algorithm is as follows:
In equation (2), 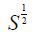 is the Cholesky decomposition of S , and the matrix of the weights W is a diagonal matrix that has zeros without diagonal elements. If the diagonal elements
of W are 1, it becomes the Mahalanobis distance. GM uses a genetic algorithm to search
for the optimal solution of W iteratively such that the maximum unbalance among the covariates of the control and
experimental groups is minimized.
is the Cholesky decomposition of S , and the matrix of the weights W is a diagonal matrix that has zeros without diagonal elements. If the diagonal elements
of W are 1, it becomes the Mahalanobis distance. GM uses a genetic algorithm to search
for the optimal solution of W iteratively such that the maximum unbalance among the covariates of the control and
experimental groups is minimized.
Ho, Imai, King, and Stuart (2007) suggest that various matching methods must be assessed to find the most robust results. This study used as many as 17 covariates, including the seven firm attributes of age, size, region, industry, IPO status, venture firm status, and affiliation status as well as ten performance indicators. First, the propensity score matching method allowed overlapping when matching the nearest cases and assigning weights in proportion to the similarity of the propensity scores. In the case of CEM, the block interval of the covariates was coarsened (widened) such that at least 70% of the firms could be matched. The GM computation took much more time than that needed by the other matching methods due to the greater computational complexity.
Table 3 shows to what extent the mean difference between recipients and non-recipients can be reduced using the PSM, CEM, and GM methods. All of the mean differences became smaller than that in the raw data. GM reduced the mean differences the most, by an average of 85%, and PSM reduced these values by about 70%. However, even if the overall average is similar, differences in individual pairs can still be large. A deviation from exact matching is referred to as an imbalance. The imbalance of the raw data was reduced the most using GM and then to a lesser extent by PSM and CEM.
When Q-Q plots (quantile-quantile plots) were drawn for each covariate variable, the balance improves as the values of the experimental group and control group are arranged close to the 45-degree line. Figure 1 shows Q-Q plots of the sales and IP rights registrations, which are relatively high in terms of the mean difference and imbalance. The matched pair values move closer to the 45-degree line than the raw data, and the values from GM move closest to the 45-degree line. Because the GM method has proved to be the best given all of the matching evaluation criteria, subsequent analyses will use the matched dataset derived from GM as a control group.
Note: In all plots, the horizontal axis represents the value of non-recipients and the vertical axis represents value of recipients.
Table 4 shows the OLS regression model using the matched dataset. The dependent variable is the value added change ( Δt+2 ) after two years, and seventeen firm-specific attribute and performance values in the supported year are controlled for as independent variables. Because this analysis applied the difference-in-differences (DID), matching method and multiple regression together, it can estimate the causal effect more robustly than a mere difference-in-differences matching method. This proves that the inferior value added growth of the recipient SMEs shown in Table 2 is not due to the treatment effects of government support.
Note: * and ** correspondingly denote statistical significance at the 5% and 1% levels.
Multiple regression estimates the effects of other covariates on the performance indicator as well. The relationship between value added in the supported year and the value added increase after two years is negative and statistically significant. That is, the incremental growth diminishes as the value added of the company increases.
OLS analyses (Table 4) are repetitively conducted with two-year increments (Δt+2) of the ten performance indicators as dependent variables. Table 5 extracts the coefficient estimates and significance of the government R&D support treatment variable to summarize the OLS results. Table 5 compares the estimation that integrates the difference-in-differences, the matching method and the OLS regression with only the DID OLS regression and DID matching estimation methods. Compared to the other outcomes, the two-stage integrated analysis (DID+Matching+OLS) demonstrates a statistically significant causal effect on most performance indicators, except for the value added increment.
Note: * and ** correspondingly denote statistical significance at the 5% and 1% levels.
In sum, government R&D support has contributed significantly to debt and equity financing of SMEs. Utilizing such funds, firms expanded their investments in intellectual property, relational assets, tangible assets and human capital. The recipients of government support achieved an approximate 5%p increase in debt financing and an increase of over 300 million won in equity financing due to their advantageous position in acquiring the government’s technology guarantees and fund of funds.9 Among the indicators of capabilities/assets, R&D investment and IP rights registrations have consistently shown considerable gains of 100%p and 30%p, respectively, while marketing investment, deemed to be strongly complementary with regard to intellectual property, gained over 20%p. Tangible assets and human capital posted small but significant gains in investment growth. However, while R&D support has served successfully as a catalyst for private-sector investment, it has not enhanced the operating performances of the recipients. Most have failed to see improvements in their value added compared to their non-recipient counterparts, even recording significant negative growth in sales and operating profit.10
Table 6 summarizes the treatment effect according to the amount of support. This table shows that the negative effects on value added, operating profit and sales are substantial and statistically significant when the support amount exceeds 500 million won. The positive effect on debt is statistically significant for all sizes and increasing moderately along with the size of support. The positive effect on equity financing is statistically significant only when the support amount exceeds 200 million won. The positive effect on R&D investment is the largest in the 100-500 million won range, and the positive effect on IP rights registrations and human capital investment is the largest when support exceeds 500 million won.
Because firms that receive government support tend to have superior capabilities to non-recipient firms, causal effects must be cautiously estimated to avoid overestimation from a simple comparison between recipients and non-recipients. However, contrary to expectations, Table 2 revealed lower growth rates of recipient firms, and an ensuing estimation of the causal effects in Table 4-6 demonstrated that they were not due to negative treatment effects in most cases. Consequently, we can suspect that government support tends to be distributed to firms with low-growth potential rather than to firms with high-growth potential. To verify our suspicion, a prediction model of the value added increment after two years is tested.
A decision-tree algorithm builds a tree top-down from a root node and partitions the data into subsets that contain similar values through a reduction of the Gini index or variance. As the nodes and layers of a decision tree increase, the predictive power of the algorithm improves but its visualization becomes more difficult. To optimize the trade-offs when presenting results, we limit the number of final nodes to less than ten. Figure 2 shows the population split into six subgroups (nodes) after applying a decision-tree model known as the „causal conditional inference trees algorithm‟ to the value added increment after two years using our 17 covariates. According to the figure, firms with three or more IP rights registrations per year (node 11) account for a mere 1% of all firms but 11% of the recipients. It is probable that they were selected based on technology competence indicators, but their value added exhibits the largest decrement of −8.7 billion won. On the other hand, small firms (node 9) with two or fewer IP rights registrations per year account for two thirds of all firms but only half of the recipients despite the fact that their value added increment is large at 100 million won on average. In other words, firms with high growth prospects were the majority but a smaller proportion were selected as recipients, while those with low growth prospects were in the minority but a larger proportion were recipients. Consequently, the value added growth of the recipients is lower than average.
Even if the average causal effect of a policy on the entire population is statistically significant, some subgroups may be affected either insignificantly or in the opposite direction. On the other hand, policies with insignificant average effects on the population may affect some subgroups either positively or negatively to a statistically significant level.
Athey et al. (2016) develop a causalTree algorithm that adopts a random-forest prediction algorithm to estimate heterogeneous treatment effects. Random-forest algorithms allow for the flexible modeling of high-dimensional interactions by building a large number of decision trees from randomly extracted bootstrap samples and averaging their predictions. Wager and Athey (2017) require the individual trees to satisfy a fairly strong condition, which they call honesty: a tree is honest if, for each training example i , it only uses the response Yi to estimate the within-node treatment effect or to decide where to place the splits, but not both. When placing splits, an honest tree approach ignores the outcome data Yi and instead trains a classification tree for the treatment assignments. Such “propensity trees” are particularly useful in observational studies because selection bias due to variations in e(x) can be minimized. This approach, which matches training examples based on the estimated propensity, is similar to propensity score matching. Although a randomized experiment is ideal, heterogeneous treatment effects for subgroups can be estimated from observational data if matched samples from the control group are very similar to those in the treatment group (Prust and Prasad, 2015).
Subgroups are derived using performance indicators and the 17 covariates and are sorted in descending order of the low treatment effects and aggregated into decimal groups. Table 7 shows the average causal effect on the value added increment for each decimal group. It compares the causal effect and observed difference for each decile group and indicates the portion of the beneficiary companies in each group, along with the average firm attribute values (across the 17 covariates) of both the experimental and control groups that belong to each decimal subgroup.
Figure 3 shows that deciles 1-4 are positive and deciles 5-10 are negative. These results imply that government support had an insignificant impact on the value added increment of the entire population, not because there was no positive impact at all but because the significant positive effect experienced by numerous recipients was offset by the negative impact experienced by the majority. The bottom decile 10 in particular shows the largest negative effect, with most firms having high value added and high equity levels, numerous IP rights registrations, long histories and high proportions of IPOs at the time of the support.
The model that estimates heterogeneous treatment effects can predict the subgroup into which each firm will fall. Accordingly, if government support assigned for recipients in the bottom six deciles (that are expected to exhibit negative effects) is redistributed to non-recipients in the top four deciles (that are expected to exhibit the opposite), positive treatment effects would expand two fold or more.
Although we introduced the prediction model and the heterogeneous causal effect model only for the value added increment in this article, we can also do this for the nine other performance indicators as well. Depending on the future application, one can select a few of the performance indicators or allocate appropriate weights to set up a customized model for analysis.
If the aforementioned models that predict the growth potential and heterogeneous causal effect are elaborated further in subsequent studies, it would be possible to select recipient firms with more growth potential and better treatment effects, which will in turn help to accelerate their growth. There exist sufficient records of support for medium-sized firms with which one can accurately predict their growth prospects and treatment effects. However, this is not the case for small firms with little experience in R&D and IP rights registrations, which means that there is not enough data, as of yet, to develop a predictive model to produce accurate estimates of policy effects in these cases. Therefore, this study suggests that experiments to expand support to smaller firms should be undertaken to explore the corresponding causal effects.
When consumer needs are ambiguous or change rapidly, the sequential completion of R&D is likely to result in a waste of time and money. Rather, the agile development method may be more effective, as it enables the early release of prototypes to potential customers so that firms receive feedback and make prompt changes. In other words, shortening the ‘time to the market’ has become imperative, and such an environment offers more opportunities to SMEs and startups whose business strengths are in speed and flexibility. To keep pace with the rapid evolution of today’s business R&D climate, government R&D support programs must be upgraded with more flexible operating systems in which active exchanges of feedback take place between those involved in R&D experiments and market verification.
First, with respect to recipient selection, a predictive model should be developed and utilized in phases while shifting away from the existing selection model, which is heavily dependent on qualitative evaluations by technology experts. As of 2016, 22 special agencies for R&D management in Korea spent more than two trillion won on operating costs, which exceeds 10% of the national R&D budget.11 Government R&D support programs for the private sector have incurred massive administrative costs on ex-ante, mid-term and ex-post evaluations, but recipients have exhibited slower growth than non-recipients. Howell (2017) found that even US programs saw no correlation between proposal review scores and corporate growth rates. Owing to the large uncertainties in the initial stages of research, even experts are unable to predict success more accurately than prediction models. Hence, it is cost-efficient to let prediction models select which firm should receive a small amount of research funding. 12 More policy experiments should be attempted to provide small grants to small firms, which have often been neglected in the recipient selection process. The government will be able to become a supporter rather than a manager by delegating the selection process to an algorithm. Only then can it focus on providing the necessary advice that can help inexperienced recipients conduct research in a more systematic manner. After the recipient firm completes the research, experts can judge the research output qualitatively and decide whether to provide follow-up funding instead of relying on the prediction model. However, it is not necessary to extend government support if the research result and commerciality are both excellent and hence the firm is likely to receive private financial support. Additional government support will be welcome only if the research result is satisfactory but its commercial viability remains ambiguous at that point.
Secondly, evaluations should be focused on broader economic performance outcomes and not only on publications, IP rights and amounts of R&D investment. Accordingly, a selection model should be developed to optimize the evaluation results. The aforementioned evidence shows that firms with three or more patents registered per year exhibit negative growth on average. The government must now discard the old belief that more patents automatically lead to greater corporate growth. The Korean government already has integrated data on ministerial R&D projects, which could be used to formulate evidence-based policies. However, insufficient action has been taken thus far with regard to policy planning, implementations and evaluations in relation to market and financial data. Attempts to realize such policy formulations should be initiated by those in ministries working for industrial innovation, with the goal of driving the fourth industrial revolution.
China has rapidly expanded R&D investment and risen to become the world’s second largest provider (no statistics available on SME R&D).
Largely due to the government’s fund of funds, Korea’s ratio of venture capital investment to GDP rose to 0.13% in 2015, standing below that of the US (0.33%) and China (0.24%) but far higher than those of Japan, Germany and France (approx. 0.03%) (Park et al., 2016).
Korea Intellectual Property Office, Intellectual Property Statistics FOCUS, 2014; 2017 (in Korean).
The distribution of corporate performance tends to skew to the right as it is influenced by large firms. As such, this raw data underwent logarithmic transformation while the raw data for value added, operating profit, and equity were used as they were considering that many of these values were negative.
Based on financial statements: tangible asset data was used as tangible assets; the sum of labor-related costs, welfare benefits, education and training costs and stock compensation was used as a proxy variable for human capital investment; the sum of R&D expenditures in income statements and manufacturing cost statements and the increments of intangible asset development costs was used as a proxy for intellectual property investment; and the sum of advertising costs, sales promotion costs, entertainment expenses and overseas marketing expenses was used as the proxy variable for relational assets.
SMEs are significantly influenced by the government’s fund of funds, while large and mid-range firms that rely on the public stock market are less influenced by whether or not they receive government support.
The analysis of the increments after three years reveals similar results. Two- or three-year performance tracking after the completion of R&D may appear to be too short to evaluate the economic effects, but according to the 2016 Survey on Technology of SMEs (2017), SMEs reported that it took an average of 10.4 months from technology development to commercialization (5.4 months for development → 5.0 months for commercialization) and an additional 7.9 months to establish sales channels. Most R&D support programs for SMEs are more akin to short-term projects that are focused on improving competitiveness in existing products, and thus enough time is given to evaluate the performance of the support program. In the empirical analysis of the US SBIR program by Edison (2010), a significant increase in sales was observed starting one year after the support. This study intended to check whether the additional government support could improve recipients’ economic performances significantly compared to those of non-recipients whose investment amounts for all capabilities including R&D were similar to those of their counterparts. In particular, value added embraces input indicators such as R&D investment, meaning that an increase in this metric would exceed the average if the operating profit does not shrink to offset the increase in inputs. Furthermore, when the evaluation targets longer periods, the effects from the respective support methods tend to dissipate due to the growing impact from other noise sources. Oh and Kim (2017) confirmed waning or stagnating effects in all indicators, except for the debt increase rate, beyond three years after the support was provided.
, & (2006). Large Sample Properties of Matching Estimators for Average Treatment Effects. Econometrica, 74, 235-267, https://doi.org/10.1111/j.1468-0262.2006.00655.x.
, , , & (2007). Matching as Nonparametric Preprocessing for Reducing Model Dependence in Parametric Causal Inference. Political Analysis, 15, 199-236, https://doi.org/10.1093/pan/mpl013.
(2017). Financing Innovation: Evidence from R&D Grants. American Economic Review, 107(4), 1136-1164, https://doi.org/10.1257/aer.20150808.
, & Why Propensity Scores Should Not Be Used for Matching, Working Paper, Harvard Institute for Quantitative Social Science, 2016, http://j.mp/2ovYGsW.
OECD. OECD, Main Science and Technology Indicators, http://www.oecd.org/sti/msti.htm, accessed October 31, 2017.